Warning: Creating default object from empty value in /home/clients/94d06d033594aadad68b65797fca0fa2/web/wp-content/themes/enfold/config-templatebuilder/avia-shortcodes/slideshow_layerslider/slideshow_layerslider.php on line 28 nlp Archives - e-Tourisme
Annecy et Lausanne, le 17/02/2023 –Nous sommes ravis d’annoncer la publication de « Comment optimiser l’usage d’OpenAI et ChatGPT ? – Le cas du tourisme » coécrit par Claudia BENASSI-FALTYS et Jean-Claude MORAND. Cet ouvrage de 106 pages, explore les récents développements du traitement du langage naturel et leur impact sur l’industrie du tourisme.
Dans ce petit ouvrage, les auteurs examinent en détail les différents aspects liés à l’utilisation de ChatGPT pour le tourisme et l’hôtellerie, notamment les nouveaux usages et comportements qui émergent suite à l’annonce d’OpenAI de proposer son outil de traitement du langage naturel. Ils se concentrent sur les façons dont ce système peut améliorer les services aux clients et comment les socioprofessionnels de cette industrie peuvent s’en emparer.
Les lecteurs découvriront un nouveau paradigme pour la gestion des connaissances ainsi que les différentes méthodes pour optimiser ChatGPT et les limites du système actuel. Les présentations et les cas présentés permettent de comprendre comment cet outil peut améliorer l’expérience client et les incidences financières du recours à ce système. L’ouvrage propose également un glossaire pour décrypter le jargon de l’intelligence artificielle.
Les auteurs Claudia BENASSI-FALTYS et Jean-Claude MORAND apportent une contribution précieuse à la littérature sur le tourisme et le traitement du langage naturel leur travail est destiné à devenir une référence importante dans le domaine.
L’ouvrage est disponible sur AMAZON.FR sous deux formats : Kindle ou broché
Détails
· ASIN : B0BVD5CW7T
· Broché : 106 pages
· ISBN-13 : 979-8374876307
· Poids de l’article : 191 g
· Dimensions : 13.97 x 0.61 x 21.59 cm
· UNSPSC-Code : 55101500
http://www.cyberstrat.net/wp-content/uploads/2013/04/Cyberstrat_logo_horizontal_340x160px1.jpg00Jean-Claude Morandhttp://www.cyberstrat.net/wp-content/uploads/2013/04/Cyberstrat_logo_horizontal_340x160px1.jpgJean-Claude Morand2023-02-17 11:42:252023-02-17 11:42:27Publication de "Comment optimiser l'usage d'OpenAI et ChatGPT ? - Le cas du tourisme>"
Cet article a été écrit avec la collaboration de Jean-Claude MONNEY – Ex Chief Knowledge Officer – Microsoft Corp, son expérience actuelle de Senior Advisor – Digital Workplace and Knowledge Management – Monney Group, LLC – Californie – USA
04/02/2023 – Je finalise, avec Claudia BENASSI, un ouvrage traitant des avancées du traitement du langage naturel et plus particulièrement des annonces faites par Micosoft et OpenAI lors de l’introduction sur le marché de ChatGPT. En introduction de cet ouvrage, nos réflexions (avec l’autre Jean-Claude) se sont portées sur les processus de gestion de la connaissance. Je soumets ici, à votre critique, quelques idées concernant l’évolution de la gestion de la connaissance en entreprise suite à l’arrivée de ces nouveaux outils. Je développe ensuite ces paradigmes dans un ouvrage a paraître très prochainement.
===========================
L’économie du savoir[1] a retenu l’attention de nombreux chercheurs du XXe siècle, sachant que certains parlent de capital cognitif[2] . D’où l’idée d’optimiser la connaissance organisationnelle en particulier dans les entreprises. Là encore, les chercheurs [en particulier NONAKA[3]] ont modélisé la connaissance pour mieux en appréhender sa transmission. Ils ont ainsi identifié deux types de connaissance : implicite et explicite.
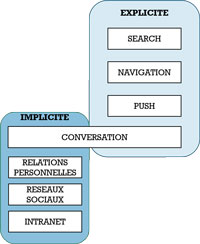
Technologies utilisées pour accéder aux connaissances explicites
La connaissance explicite se réfère à la connaissance qui peut facilement être articulée, écrite ou codifiée, comme les faits, les chiffres et les instructions. C’est une connaissance qui peut facilement être partagée et communiquée aux autres. Avec la numérisation grandissante du monde, cette connaissance qui autrefois était dans les livres, se retrouve sous toute les formes digitales, fichier texte, courriel, chat, présentations, site web, vidéo, photo, code programme, etc. Les moyens d’accès à cette connaissance sont également nombreux : la recherche avec de moteurs dédiés, la navigation sur les sites web, les flux RSS ou les notifications reçues sur abonnement.
L’arrivée d’assistants capables de capter et de partager les connaissances presque de la même manière qu’un humain peut le faire va profondément modifier notre processus d’acquisition et de mise en œuvre des connaissances. Une nouvelle forme de conversation est maintenant possible pour extraire les connaissances explicites et ce depuis des bases de données de mieux en mieux renseignées.
Notons que les définitions des connaissances implicites ou tacites ne sont pas très éloignées. La connaissance tacite est la connaissance intuitive et inconsciente que nous possédons, qui est difficile à formaliser ou à expliquer verbalement. Elle est souvent acquise par l’expérience et la pratique, et peut être transmise de manière informelle. La connaissance implicite, quant à elle, est la connaissance qui est sous-jacente à nos comportements et actions, mais qui n’est pas consciemment considérée ou exprimée. Elle peut être découverte et articulée à travers des processus tels que la réflexion et la verbalisation. En résumé, la connaissance tacite est inconsciente et la connaissance implicite est inconsciente mais peut être rendue consciente.
Les exemples de connaissances implicites incluent le savoir-être, le savoir-faire, les savoir-pourquoi, les savoir-quoi et les savoir-qui. Dans ‘entreprise, on identifie des experts en matières, ou des communautés de savoir qui sont les sources de ce type de connaissance. Depuis l’avènement d’Internet, des moyens techniques ont été utilisés pour améliorer les transferts de connaissance implicite. C’est loin d’être parfait, mais les capacités de mémorisation des ordinateurs pallient souvent les pertes de mémoires des humains. Depuis le Web 2.0 fin 2004.[4]
Jusqu’à présent le processus de découverte de la connaissance implicite reposait principalement sur la socialisation.
L’échange de la connaissance s’effectuait principalement entre les individus lors de travail en commun, de discussions informelles, de coaching et de feedback. Les réseaux sociaux, les discussions sur les forums spécialisés et les informations mises à disposition sur les intranets des entreprises ont été des vecteurs d’accélération ou tout simplement de la mise à disposition des connaissances implicites.
L’arrivée d’assistants intelligents dotés de connaissances presque sans limites et surtout capables de les restituer avec des mots modifie un peu le processus de transfert des connaissances. Les conversations réservées aux humains s’étendent aux agents virtuels nous permettant de définir un nouveau paradigme en ce qui concerne la gestion de la connaissance.
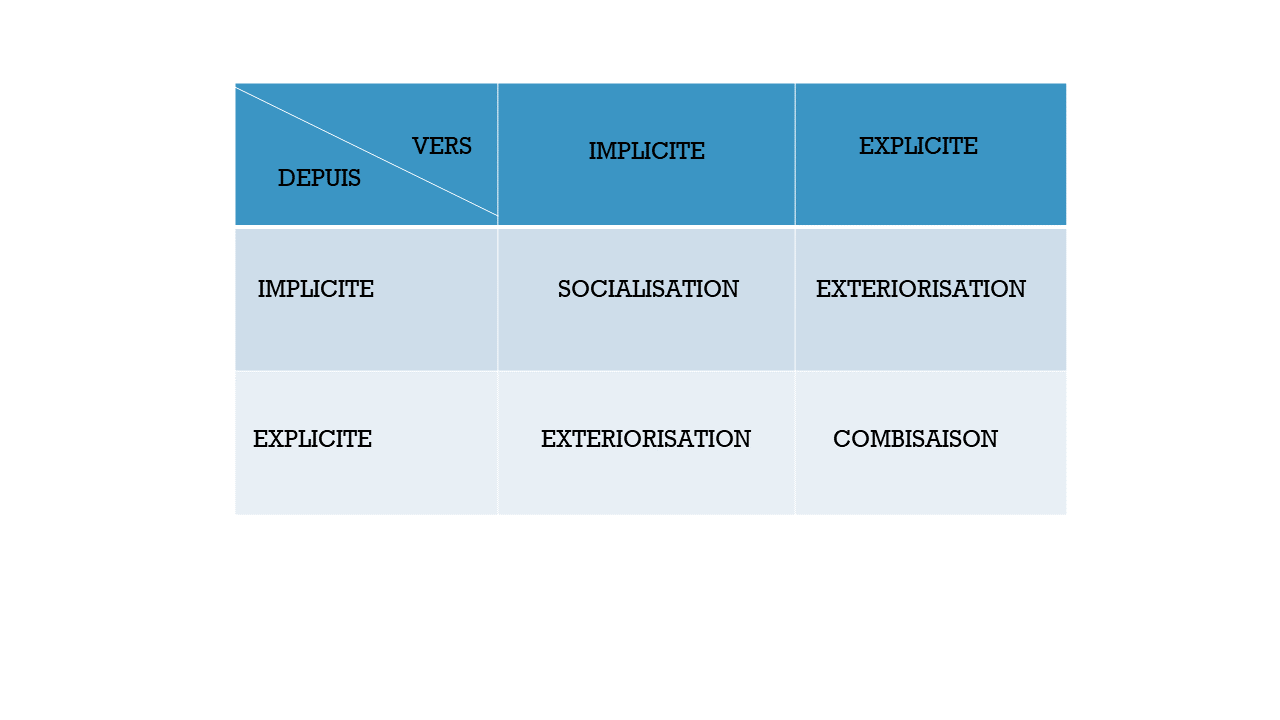
Nonaka a modélisé le processus de transfert des connaissances autour de ces deux concepts en partant du principe qu’une connaissance parfaite devait prendre en compte les deux formes : implicite et explicite.
Nous avons abordé l’apport de la socialisation. L’extériorisation consiste à transformer les connaissances implicites en connaissances explicites : un processus qui se réalisait principalement lors des échanges entre les humains. L’arrivée d’agents virtuels capables d’échanger en langage naturel avec les humains rend la tâche beaucoup facile. Certes, cela ne s’applique que modérément aux tâches manuelles, mais un grand pas est franchi !
Processus de gestion de la connaissance selon Nonaka
En l’absence de transactions automatisées, la combinaison c’est-à-dire la mise en œuvre ou la réutilisation de la connaissance reste un privilège des humains.
Le tourisme et l’hôtellerie sont des secteurs où la qualité du service est très importante. C’est aussi une économie de la connaissance. Connaissance qui doit être transmise avant et durant le séjour des touristes. Cependant, cette industrie emploie de nombreux saisonniers qui ne disposent pas forcément de ces connaissances. Internet a largement pallié à cet inconvénient depuis les années 1990 en augmentant les possibilités de diffusion des connaissances explicites, ensuite, les technologies du Web 2.0 ont fortement contribué à l’émergence des plateformes de réservation comportant des avis client.
Les logiciels de réseaux de neurones[5] viennent compléter ces approches en donnant un accès quasi illimité à des données non structurées issues d’une multitude de sources que les touristes ne connaissent pas.
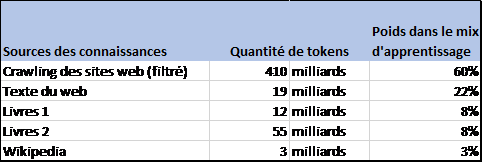
Nous avons donc accès en langage naturel à une grosse base de connaissance comportant au moins 175 millions de paramètres[6]. Pour obtenir ce résultat OpenAI a crawlé[7] un grand nombre de sites web pour alimenter sa base de connaissance. Les données extraites ont été épurées[8] des propos violents, racistes et à connotation sexuelle par des humains.
Sets de données utilisées pour entrainer OpenAI/ChatGPT
[2] « Cette notion trouve son origine dans les travaux de l’économiste autrichien Fritz Machlup (1902-1983) et la publication en 1962 de son livre The production and distribution of knowledge in the United States où il met en évidence le poids croissant de l’industrie de la connaissance dans l’économie américaine. » – source : https://www.toupie.org/Dictionnaire/Capitalisme_cognitif.htm
[3] Nonaka et H. Takeuchi, La connaissance créatrice : la dynamique de l’entreprise apprenante, De Boeck Université, Bruxelles, 1997.
[4] Le terme « Web 2.0 » a été introduit en 2004 par Tim O’Reilly pour décrire une série de tendances et de technologies qui ont transformé le World Wide Web en un lieu où les utilisateurs peuvent créer et partager du contenu, plutôt que simplement en consommer.
[6] Language models are few-shot learners -T. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, and others. arXiv preprint arXiv:2005.14165 (2020)
[7] Crawler : des robots visitent les sites web et stockent ensuite les données qui sont analysées à l’aveugle par un logiciel de réseau de neurones (Neural network).
[8] OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic – https://time.com/6247678/openai-chatgpt-kenya-workers/
https://www.cyberstrat.net/wp-content/uploads/2023/02/synapses-iStockphoto-1053434168-scaled.jpg14392560Jean-Claude Morandhttp://www.cyberstrat.net/wp-content/uploads/2013/04/Cyberstrat_logo_horizontal_340x160px1.jpgJean-Claude Morand2023-02-04 18:24:342023-02-05 10:30:44Allons-nous vers un nouveau paradigme de la gestion de la connaissance en entreprise ?
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager